
ゼロから作るDeep Learning
誤差逆伝搬法(バックプロパゲーション)の導出
昨今注目を集めているAI(人工知能)を学びたいと思い立ち、ディープラーニング(Deep Learning、深層学習)と呼ばれるAIの数理モデルである多層構造のニューラルネットワークを書籍「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」を参考にを独習していきたいと思います。本書籍ではプログラミング言語としてPythonが利用されていますが、本項ではJavaScriptで実装していきます。

目次
- 準備1:行列の和と積を計算する関数の実装
- 準備2:ベクトルと行列の積を計算する関数の実装
- 準備3:多変数関数の数値微分と極小値の探索
- 1.1層ニューラルネットワークの実装(バイアスなし、活性化関数なし、学習なし)
- 2.1層ニューラルネットワークへのバイアスと活性化関数の追加
- 3.1n1型2層ニューラルネットワークの実装(学習なし)
- 4.1変数関数を学習させてみる1:勾配法による学習計算アルゴリズム
- 5.1変数関数を学習させてみる2:勾配法による学習計算アルゴリズムの実装
- 6.1変数関数を学習させてみる3:ニューロン数による学習効果の違い
- 7.誤差逆伝搬法(バックプロパゲーション)の導出
- 8.順伝播型ニューラルネットワーク「FFNNクラス」の実装(JavaScript)
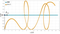
- 9.三角関数のサンプリング学習(WebWorkersによる並列計算)
- 10.学習後の各層ニューロンの重みの可視化
- 11.層数とニューロン数による学習効果の違い
誤差逆伝搬法(バックプロパゲーション)の導出
書籍「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」では誤差逆伝搬法の概念を直感的に解説を行うため「計算グラフ」と呼ばれるダイアグラムを用いています。この方法は概念を把握する際には有用ですが、実際にプログラミングを行う際には具体的な表式を与えません。 本項では、プログラミングに必要な漸化式の導出を行います。
復習
第l層i番目のニューロンを
と表わすとします。第l+1層i番目ニューロン
は第l番目の各パラメータを用いて
と表すことができます。
は活性化関数、
は活性化関数を通す前のニューロン値、
と
は重みとバイアスです。
重みとバイアスは損失関数
(本項ではLではなくEと表します)
が小さくなる方向へ学習ごとに更新させます。具体的には各重みとバイアスに対する勾配(偏微分)が与えられれば、次のアルゴリズムで重みとバイアスを更新させることができます。
各勾配は重みあるいはバイアスをほんの僅かずらすことで得られる損失関数値の増減から見積ることができますが、各勾配を計算するたびに入力から出力を得るための全計算を行う必要がでてきます。そこで、効率よく勾配を計算するために考案されたのが誤差逆伝搬法(バックプロパゲーション)と呼ばれる計算アルゴリズムです。誤差逆伝搬法は損失関数を各層ごと入出力関数の合成関数とみなして損失関数の微分値を計算する手法です。合成関数の微分の特性を利用することで、出力層から入力層に向かう方向で漸化式を導くことができ、この逆向きの漸化式から「逆伝搬」の名称がついていると考えられます。着目するのは次の量です。
この量は第l層i番目のニューロン値に対する損失関数の勾配を表します。本書ではデルタ値と呼ぶことにします。このデルタ値はネットワーク上のすべてのニューロンごとに定義することができ、第l層と第l+1層のデルタ値には次の関係を導くことができます(ここで合成関数の微分が活躍します)。
これは
と
の関係式を表す漸化式です。その他の変数は通常の「入力→出力」の計算時(以後、順伝搬と呼ぶことにします)に計算済みなので、出力層におけるデルタ値が与えられれば、すべての層のデルタ値を計算することができます。あとはこのデルタ値を用いて、重みとバイアスに対する損失関数の勾配を計算するだけです。それぞれ、合成関数の微分を利用すると次のとおりに得られます。
この誤差逆伝搬法を用いると重みと勾配の計算を層数やニューロン数によらず、1回の逆伝搬計算で各層のデルタ値が得られるため、層数とニューロン数が大きくなるほど効果は絶大となります。 以上誤差逆伝搬法の計算アルゴリズムの一般論です。具体的な活性化関数に対する計算アルゴリズムは次項で示します。